MVHumanNet++: A Large-scale Dataset of Multi-view
Daily Dressing Human Captures with Richer Annotations
for 3D Human Digitization
1. FNii, CUHKSZ 2. SSE, CUHKSZ

Nowadays, 3D heads can be easily digitalized with high-fidelity geometry and texture, like the setup used in FaceScape. In this work, we proposed EMS, a learning-based approach, which can further reconstruct 3D eyebrows from just the frontal-view image. (a) the input image. (b) the cropped eyebrow image from (a). (c) our reconstructed fiber-level 3D eyebrow model rendered with multiple views. (d) the cropped rendering of (e) for comparison with (b). (e) putting our result on the textured 3D head can further improve the realism of face digitalization.
Abstract
In this era, the success of large language models and text-to-image models can be attributed to the driving force of large-scale datasets. However, in the realm of 3D vision, while significant progress has been achieved in object-centric tasks through large-scale datasets like Objaverse and MVImgNet, human-centric tasks have seen limited advancement, largely due to the absence of a comparable large-scale human dataset. To bridge this gap, we present MVHumanNet++, a dataset that comprises multi-view human action sequences of 4,500 human identities. The primary focus of our work is on collecting human data that features a large number of diverse identities and everyday clothing using multi-view human capture systems, which facilitates easily scalable data collection. Our dataset contains 9,000 daily outfits, 60,000 motion sequences and 645 million frames with extensive annotations, including human masks, camera parameters, 2D and 3D keypoints, SMPL/SMPLX parameters, and corresponding textual descriptions. Additionally, the proposed MVHumanNet++ dataset is enhanced with newly processed normal maps and depth maps, significantly expanding its applicability and utility for advanced human-centric research. To explore the potential of our proposed MVHumanNet++ dataset in various 2D and 3D visual tasks, we conducted several pilot studies to demonstrate the performance improvements and effective applications enabled by the scale provided by MVHumanNet++. As the current largest-scale 3D human dataset, we hope that the release of MVHumanNet++ dataset with annotations will foster further innovations in the domain of 3D human-centric tasks at scale.
Overview
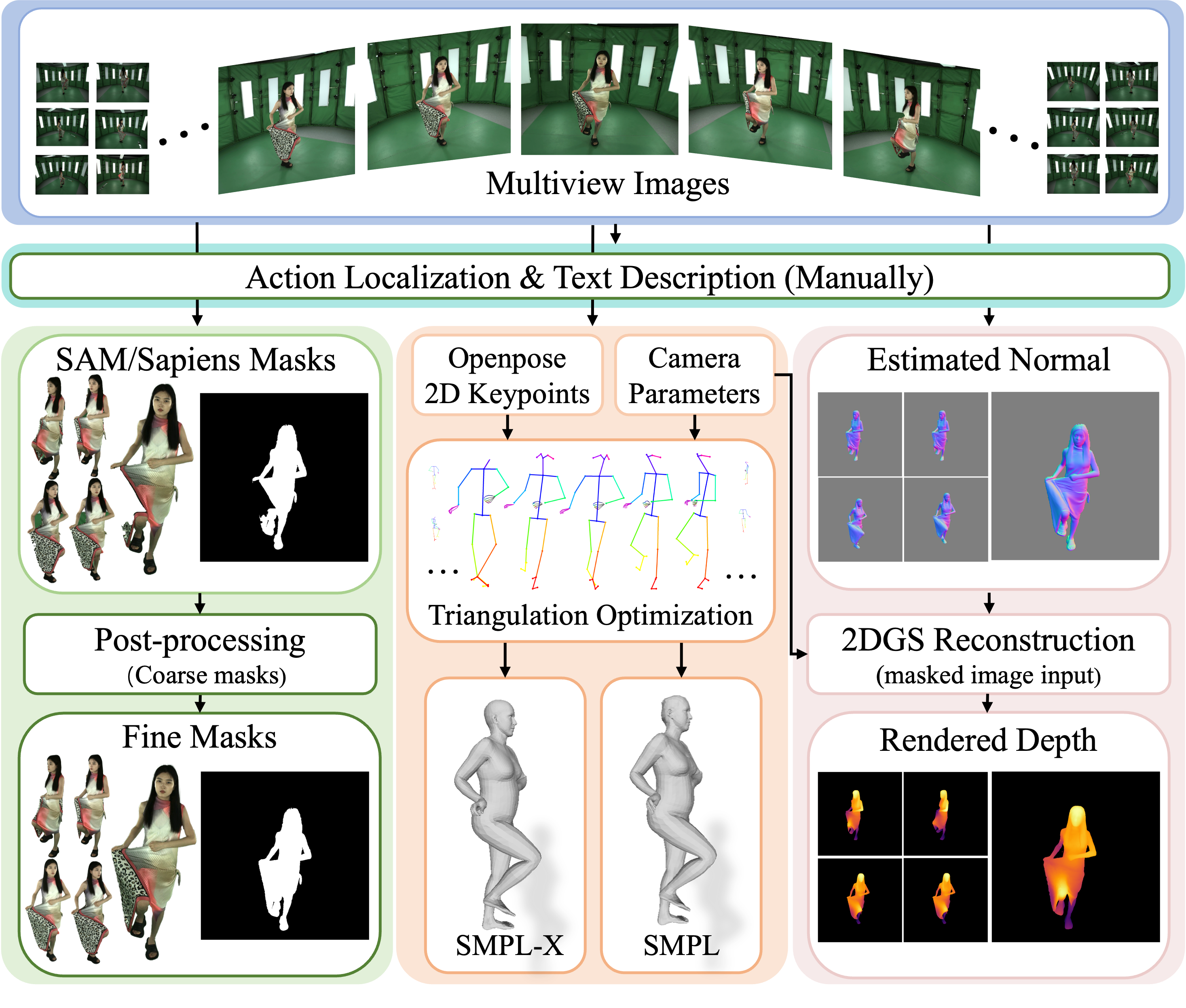
Data annotation pipeline. The manual and automatic annotation pipeline for action localization, text description, masks, 2D/3D keypoints, parametric models, normal maps and depth maps for building comprehensive 4D human datasets.
New Masks

Mask processing visualization. From left to right in each column are the input image, SAM segmentation result, Sapiens segmentation result, and final mask after post-processing.
New SMPLX

SMPLX comparsion results. The zoom-in boxes with blue dot lines show the annotation quality before optimization and the pink ones show quality improvements. Previous SMPLX estimation results show ankle twisting and self-intersection artifacts in the left column images, as well as misalignment in the right column images. In contrast, our optimized pipeline incorporates a body pose prior to regularize human pose estimation, effectively addressing these limitations.
Normal Map

Normal visualization. From left to right of each column are the original image, Sapiens estimated normal, 2DGS rendered normal without Sapiens normal, and 2DGS rendered normal with Sapiens normal input.
Depth Map

Visual results of depth maps rendered from normal-refined 2DGS.
Reference
@article{li2025mvhumannet++,
title={MVHumanNet++: A Large-scale Dataset of Multi-view Daily Dressing Human Captures with Richer Annotations for 3D Human Digitization},
author={Li, Chenghong and Liao, Hongjie and Zhi, Yihao and Yang, Xihe and Sun, Zhengwentai and Chang, Jiahao and Cui, Shuguang and Han, Xiaoguang},
journal={arXiv preprint arXiv:2505.01838},
year={2025}
}